Building Better Data Pipelines with Python and GNU Parallel
4 November 2023
/
6 min read
When processing data, I often find myself writing a Python script to solve the whole problem. However, using command line tools and working in harmony with the Unix philosophy can help reduce complexity and increase reusability.
Let’s take a look at a problem I came across recently, comparing a 100% Python solution to one that takes advantage of command line programs such as GNU parallel.
Table of Contents
The problem
Given a CSV file containing data for Spotify artists that looks like this:
artists.csv
id,name,spotify_uri
0,Drake,spotify:artist:3TVXtAsR1Inumwj472S9r4
1,Bad Bunny,spotify:artist:4q3ewBCX7sLwd24euuV69X
2,Ed Sheeran,spotify:artist:6eUKZXaKkcviH0Ku9w2n3V
3,The Weeknd,spotify:artist:1Xyo4u8uXC1ZmMpatF05PJ
4,Taylor Swift,spotify:artist:06HL4z0CvFAxyc27GXpf02Find the YouTube channel for each artist and store the data in a SQLite database with the following schema:
artist.db
CREATE TABLE artist (
id INTEGER PRIMARY KEY,
name TEXT,
spotify_uri TEXT,
youtube_url TEXT
);Original Python solution
Here is my original script.
The get_channel function is simplified here,
but in reality it uses Selenium
to find a channel by searching YouTube, which could take 10–20 seconds.
get_channel_v1.py
import pandas as pd
import argparse
import time
import random
import sqlite3
# Return the YouTube channel URL for a given artist using their name
def get_channel(artist):
time.sleep(random.random())
return 'https://www.youtube.com/@%s' % artist['name'].replace(' ', '')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# Path to the CSV file to read from
parser.add_argument('--input-csv', type=argparse.FileType('r'))
# Path to the SQLite database to write to
parser.add_argument('--output-db', type=str)
args = parser.parse_args()
# Read data from the CSV
df = pd.read_csv(args.input_csv)
# Run get_channel for each artist in the CSV
df['youtube_url'] = df.apply(get_channel, axis=1)
# Write the data to the database
con = sqlite3.connect(args.output_db)
cur = con.cursor()
for _, artist in df.iterrows():
cur.execute(
'INSERT INTO artist (name, spotify_uri, youtube_url) VALUES (?, ?, ?)',
(artist['name'], artist['spotify_uri'], artist['youtube_url'])
)
con.commit()This script has a couple of immediate problems:
- If an error occurs while processing one row, the program will crash and no progress will be saved.
- The program is slow and could be sped up using concurrency (running
get_channelfor multiple artists at the same time)
Amended Python solution
These issues can be solved using Python’s
concurrent.futures
module and a try … except.
This function processes the data using five parallel threads. It looks complicated but essentially, it submits each artist to be processed and then saves the results into the dataframe.
def get_many_channels(df):
df['youtube_url'] = ''
with futures.ThreadPoolExecutor(max_workers=5) as executor:
future_channels = [
(index, executor.submit(get_channel, row))
for index, row in df.iterrows()
]
for (index, future_channel) in future_channels:
try:
channel = future_channel.result(timeout=5)
df.at[index, 'youtube_url'] = channel
except Exception:
continue
return dfWe simply ignore any row that results in an error, though it would not be too much more effort to add some logic allowing a number of retries.
Now we can replace this line from before:
df['youtube_url'] = df.apply(get_channel, axis=1) with this:
df = get_many_channels(df) and we have a much faster and less error-prone script.
However, our script is growing and gaining complexity. Ideally it would have one responsibility (finding YouTube channels) but now it is:
- parsing command line arguments
- loading data from a CSV file
- handling concurrency with
futures - preventing exceptions from crashing the program
- storing data in a SQLite database
Another problem is the lack of flexibility in the program’s execution. We cannot use alternative input and output methods or customise parameters such as the number of parallel workers to use. These features could be added with additional command line arguments, but would continue to increase the complexity of the script.
Let’s try to simplify the program using GNU parallel!
Some shell concepts
stdin, stdout and stderr
These are the communication channels that are used to pass data between programs in the shell, and we can think of them as just blocks of text. A typical shell program looks like this:
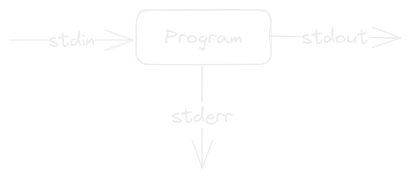
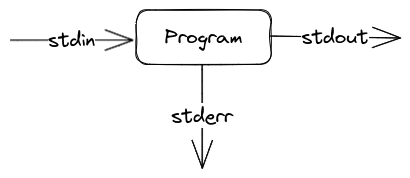
The pipe | operator
This operator takes the stdout of one program and passes it to another as stdin.
> cat artists.csv | grep Weeknd
3,The Weeknd,spotify:artist:1Xyo4u8uXC1ZmMpatF05PJcat reads a file and sends this to stdout.
grep searches through stdin, sending any lines matching the given pattern to stdout.
| sits between the two commands, passing cat’s output to grep.


Using GNU parallel
First of all, we’ll rewrite our Python script to only take in the data for one artist, process this data and then save it to our database.
get_channel_v3.py
import argparse
import time
import random
import sqlite3
def get_channel(name):
time.sleep(random.random())
return 'https://www.youtube.com/@%s' % name.replace(' ', '')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--name', type=str)
parser.add_argument('--spotify-uri', type=str)
parser.add_argument('--output-db', type=str)
args = parser.parse_args()
# Find the YouTube channel for the artist
channel = get_channel(args.name)
# Write the data to the database
con = sqlite3.connect(args.output_db)
cur = con.cursor()
cur.execute(
f'INSERT INTO artist (name, spotify_uri, youtube_url) VALUES (?, ?, ?)',
(args.name, args.spotify_uri, channel)
)
con.commit()Now we can execute the script using this command:
cat artists.csv \
| parallel --skip-first-line --colsep , --jobs 5 \
python get_channel_v3.py --output-db=artist.db --name={2} --spotify-uri={3}\ is used to break the command into multiple lines for readability
cat artists.csv | reads our CSV file and sends it to parallel
How does parallel work?
Parallel is a command line tool for executing tasks concurrently.
It can be installed like this:
sudo apt install parallelRunning parallel typically looks like this:
parallel <args> <command to run in parallel>Let’s look at the arguments we are using:
--skip-first-line this prevents parallel from processing the CSV header.
--colsep , this splits each line of the input on commas and lets us access these values like {1} or {2} etc.
--jobs 5 this tells parallel to process a maximum of 5 tasks simultaneously.
python get_channel_v3.py --output-db=artist.db --name={2} --spotify-uri={3} runs our Python script, passing in the name and Spotify URI for an artist.
We are getting somewhere, but
Now we are getting concurrency for free with parallel, only one artist will be affected if the script crashes, we have more freedom in how we input data and our code is much simpler!
However, there are still a couple of problems. First, we never solved the issue of allowing the script to output to different formats. Second, we have now made it more difficult to process a CSV in one go without the help of a tool like parallel to split the data into individual rows.
Also, using parallel to process CSVs in this way is not a great solution as it uses the order of the columns rather than their headers and there are edge cases where simply splitting a row on commas will not work.
For example, Tyler, The Creator would be incorrectly processed even if the row was formatted correctly like this:
106,"Tyler, The Creator",spotify:artist:4V8LLVI7PbaPR0K2TGSxFFUseful building blocks
Let’s create a couple of reusable solutions for these problems.
Handling CSVs with parallel
Normally, when we pass a CSV into parallel, each row is processed independently, so it loses the helpful context of the column headers.
To solve this, we can use some bash magic to repeat the header above every row in the CSV, and then we can tell parallel to process the data in pairs of lines.
cat artists.csv \
| (read header; while IFS= read -r line; do echo "$header"; echo "$line"; done) \
| parallel --pipe -n 2 <command>Two lines are passed to the command by specifying -n 2,
and the --pipe argument tells parallel to pass its input as stdin to <command>,
similar to the behaviour of the pipe operator.
This pattern means that our script can always expect to receive a complete CSV as input, so it can also be used to process a CSV in one go if parallel is not required.
Converting CSV to SQL insert
Rather than have our Python script interact with SQLite directly, we’d like for it to output its data in a standard format that can be reformatted to our needs. To achieve this, we will refactor the script to output a CSV, which we can convert to SQL insert commands using this utility script:
to_sql.py
import pandas as pd
import sys
# Convert dataframe row to SQL values (only handles strings and integers)
def to_sql_values(row):
values = [
str(value) if isinstance(value, int)
else '"%s"' % value
for value in row.values
]
return '(%s),' % ','.join(values)
if __name__ == '__main__':
if len(sys.argv) < 2:
print('Usage: python to_sql.py <table_name>', file=sys.stderr)
sys.exit(1)
table_name = sys.argv[1]
# Read data from stdin
df = pd.read_csv(sys.stdin)
# Generate SQL insert statement
insert = 'INSERT INTO artist (%s) VALUES ' % ','.join(df.columns)
values = df.apply(to_sql_values, axis=1).str.cat(sep=' ')
statement = insert + values[:-1] + ';'
# Output to stdout
print(statement)This script takes a CSV on stdin, converts this to an SQL insert command string using the specified table name, and outputs it to stdout.
For example,
cat artists.csv | python to_sql.py artistwould output: (formatted for readability)
INSERT INTO artist (id,name,spotify_uri) VALUES
(0,"Drake","spotify:artist:3TVXtAsR1Inumwj472S9r4"),
(1,"Bad Bunny","spotify:artist:4q3ewBCX7sLwd24euuV69X"),
(2,"Ed Sheeran","spotify:artist:6eUKZXaKkcviH0Ku9w2n3V"),
(3,"The Weeknd","spotify:artist:1Xyo4u8uXC1ZmMpatF05PJ"),
(4,"Taylor Swift","spotify:artist:06HL4z0CvFAxyc27GXpf02");The final product
get_channel.py
import sys
import pandas as pd
import time
import random
def get_channel(artist):
time.sleep(random.random())
channel = 'https://www.youtube.com/@%s' % artist['name'].replace(' ', '')
return pd.Series({
'name: artist['name],
'spotify_uri: artist['spotify_uri],
'youtube_url': channel
})
if __name__ == '__main__':
df = pd.read_csv(sys.stdin)
df.apply(get_channel, axis=1).to_csv(sys.stdout, index=False)This script is much simpler than before, only interfacing with the input and output using CSV formats, which pandas can handle for us. (Though if the script had any configurable parameters, it would still be necessary to use a library such as argparse.)
cat artists.csv \
| (read header; while IFS= read -r line; do echo "$header"; echo "$line"; done) \
| parallel --pipe -n 2 --jobs 5 'python get_channel.py | python to_sql.py artist' \
| sqlite3 artist.dbThe command python get_channel.py | python to_sql.py artist
generates an SQL insert command for each row of the CSV,
and we can pass this multi-part command to parallel by wrapping it in quotes.
This output is then piped to sqlite3, which executes the SQL commands.
Conclusion
We have refactored our solution to follow the principles of the Unix philosophy, summarised by Peter H. Salus as:
- Write programs that do one thing and do it well.
- Write programs to work together.
- Write programs to handle text streams, because that is a universal interface.
By writing our script with a single responsibility in mind and by working with shell programs such as cat, parallel and sqlite3, we have created a simpler, more flexible and more reusable solution.